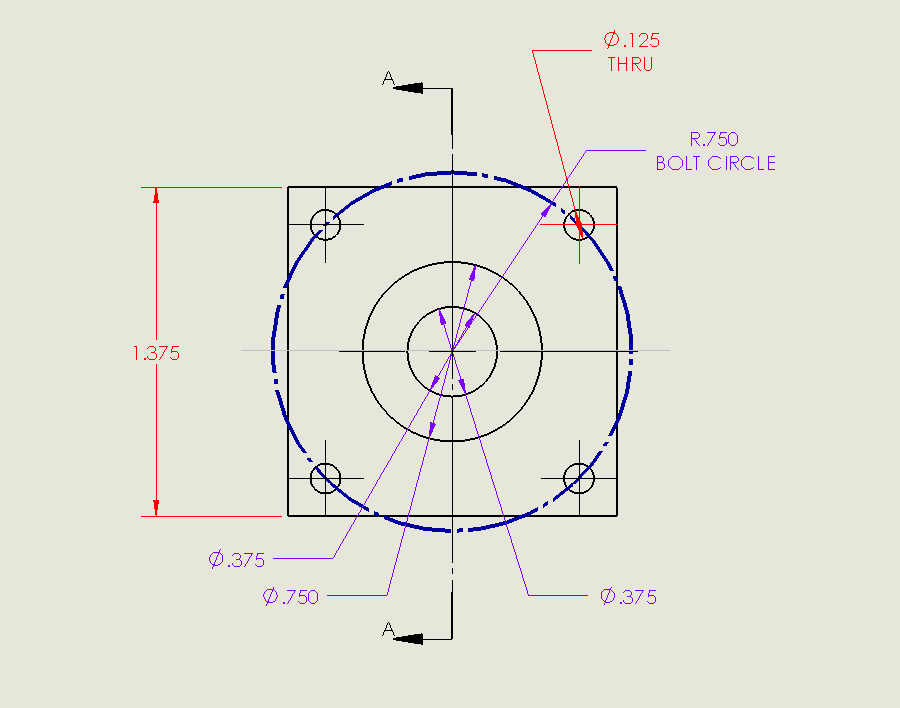
SOLIDWORKS Inspection使用OCR編輯器創建自定義詞典字體
日期:2022-05-25 16:06:33 發布者: 瀏覽次數:次
SolidWorks Inspection提供了多個詞典字體,為OCR引擎提供准確的結果,但這些詞典字體不可能覆蓋所有用戶所使用的圖紙文檔。當提供的詞典字體不能滿足我們的工作需求時,可以使用OCR編輯器來自定義詞典。本文介紹了OCR編輯器的使用方法和一些注意事項。
【概述】
Inspection是一款出具首件檢查報告(FAI)的工具,他可以極大地簡化及自動生成檢查工程圖立即按序號和質量檢查報告的過程。Inspection獨立版可以讓非CAD用戶,通過PDF或TIFF工程圖文檔創建帶零件序號的工程圖和質檢報告。
Inspection 獨立版對PDF和TIFF工程圖信息的識別是基於OCR(光學字符識別引擎)將捕捉到的特征與詞典進行比較,以提取並解釋所獲取的信息。Inspection提供了多個詞典字體,為OCR引擎提供了准確的結果。
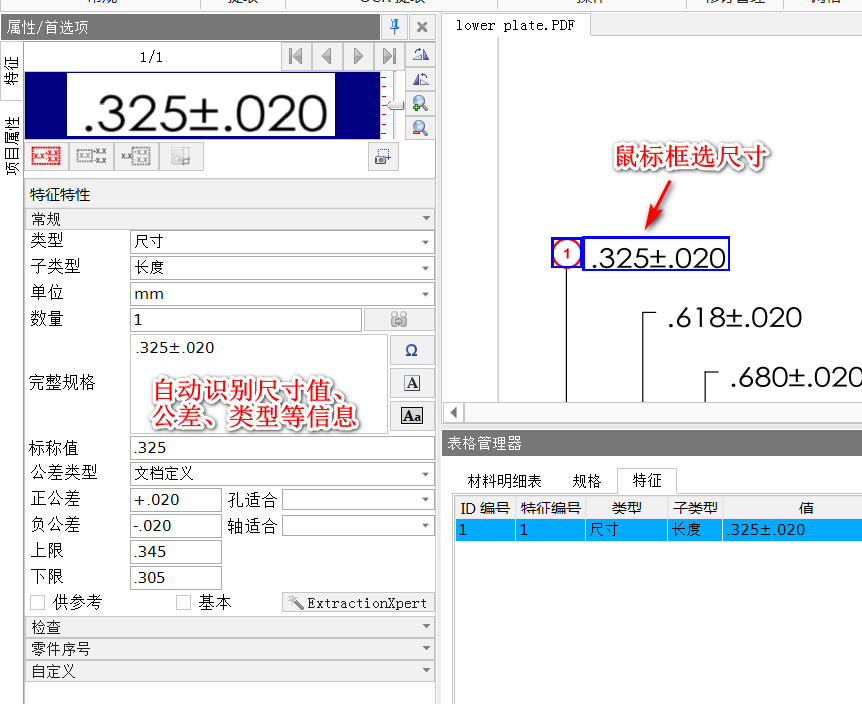
圖 1 OCR示例
默認的尺寸詞典字體報包括:
·Standard 標准字體庫適用於主流標准的工程圖文件;
·Acad 對於細印刷體較適配,例如AutoCAD或老版本的Pro/e工程圖;
·CATIA 適用於CATIA生成的工程圖;
·NX1 適用於Siemens NX或Unigraphics,同樣適用於印刷體工程圖;
·Century Gothic 適用於Century Gothic字體的工程圖;
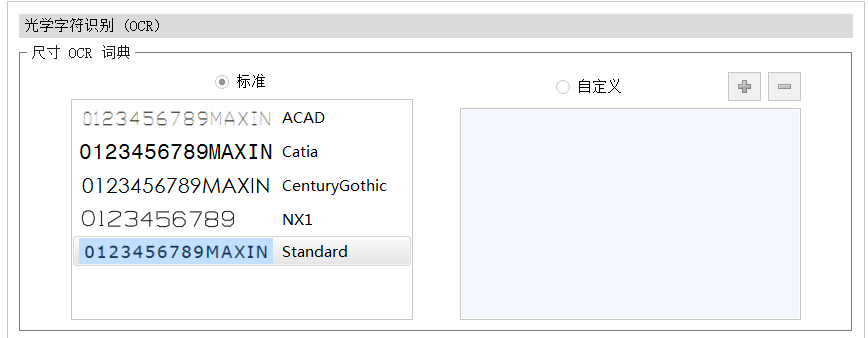
圖 2 OCR選項界面
當Inspection提供的詞典字體不能滿足我們的工作需求時,可以使用OCR編輯器來創建自定義詞典。OCR編輯器可以讓用戶從已有的PDF和TIFF文檔生成自定義的詞典,通過框選特征然後指定我們期望的值實現。
【注意事項】
1.OCR引擎對詞典字體的匹配非常嚴苛,稍有不同就可能識別錯誤,選擇相匹配的詞典字體有助於提高我們的工作效率
2.為了快速提取特征,我們可以在工程圖可空白處添加所有的特征和符號,以空格進行區分;
3.字母、數字或符號都可以使用提取分別提取並指定值,也可以使用自動提取,框選多個特征,再分別指定正確的值;
4.提取完成後可以刪除或修改不正確的值;
5.為了獲得最佳效果,推薦重復提取相同的特征3 ~ 5次;
6.目前僅支持水平和垂直方向的特征,帶有角度的特征還無法捕捉;
7.詞典默認保存在C:\ProgramData\SOLIDWORKS\SOLIDWORKS Inspection 2018 Standalone\TrainableOCR文件夾下;
【操作步驟】
1.啟動Inspection 獨立版,在文件欄裡找到OCR編輯器,點擊進入;
2.單擊添加工程圖,打開我們的工程圖文件;本文所使用的工程圖已經把所需要的特征添加到了左上角空白處,如圖3;
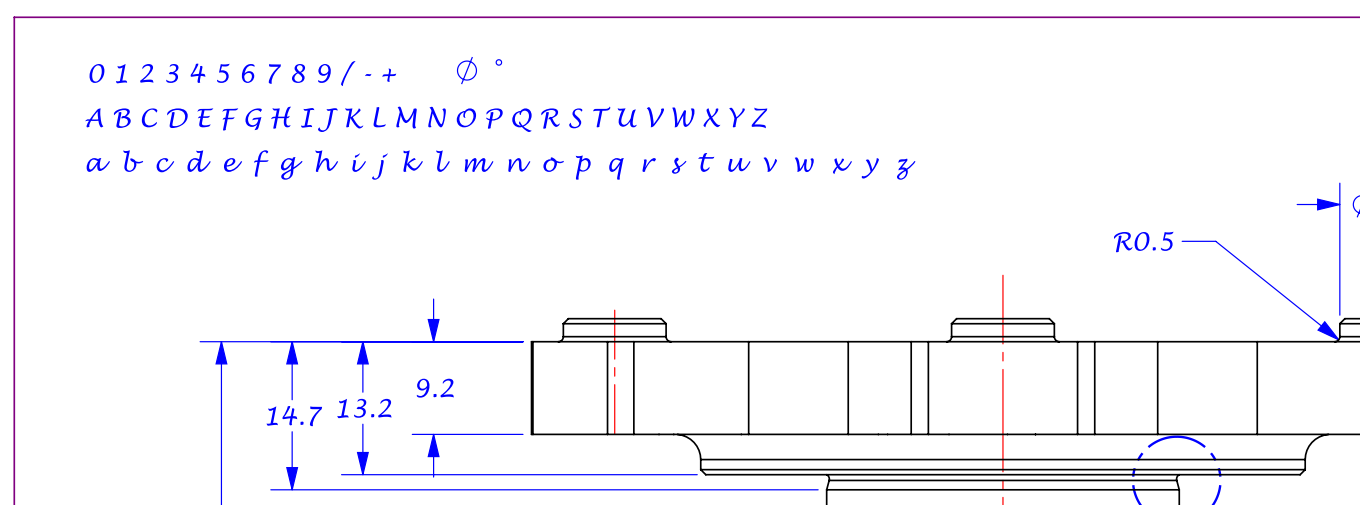
圖 3帶字母、數字及符號
3.單擊提取,手動款選單個特征,發現在下方框特征裡的值一欄紅色顯示問號,如圖4;我們可以在左側提取欄中輸入正確的值。字母、數字和常見的符號可以直接鍵盤輸入。一些特殊的符號可以單擊值域右側Ω【Insert Symbol】圖標,如圖5,插入所需的符號。

圖 4框特征

圖 5提取欄
4.可以使用自動提取框選整行特征,系統會自動進行識別賦值;檢查每個特征是否識別正確,對不正確的特征可進行修改或刪除後重新提取識別;
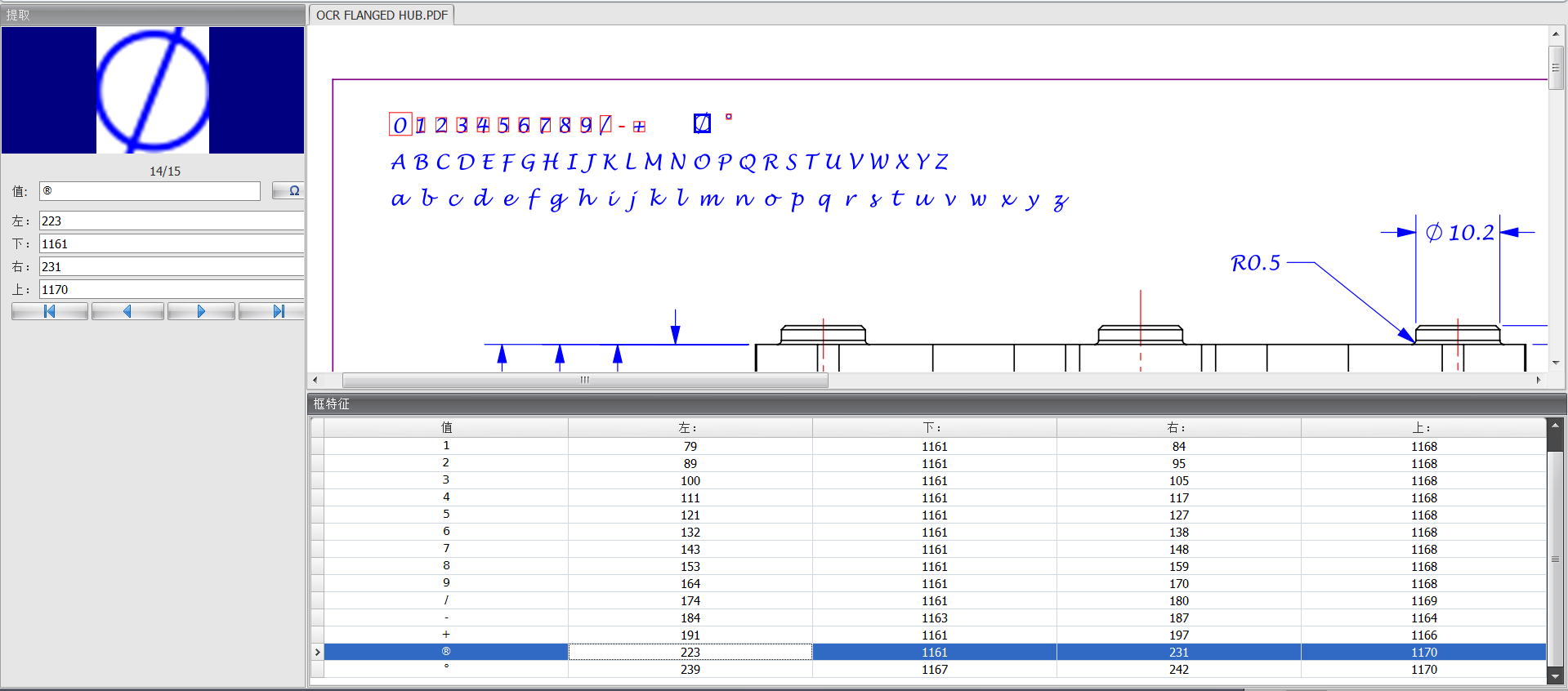
圖 6自動提取
5.在正確提取了所有的特征後,單擊保存,選擇保存地址確定後,彈出圖7對話框則說明保存成功,單擊確定;
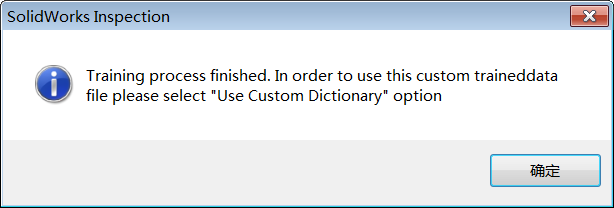
圖 7彈出對話框
6.回到Inspection Standalone界面,單擊【主頁】/【選項】/【項目選項】/【OCR】,在尺寸OCR一欄勾選自定義,單擊+,找到我們剛保存的詞典文件,注釋OCR詞典欄有需要也可以同樣添加自定義詞典,兩者可用同一個詞典文件;
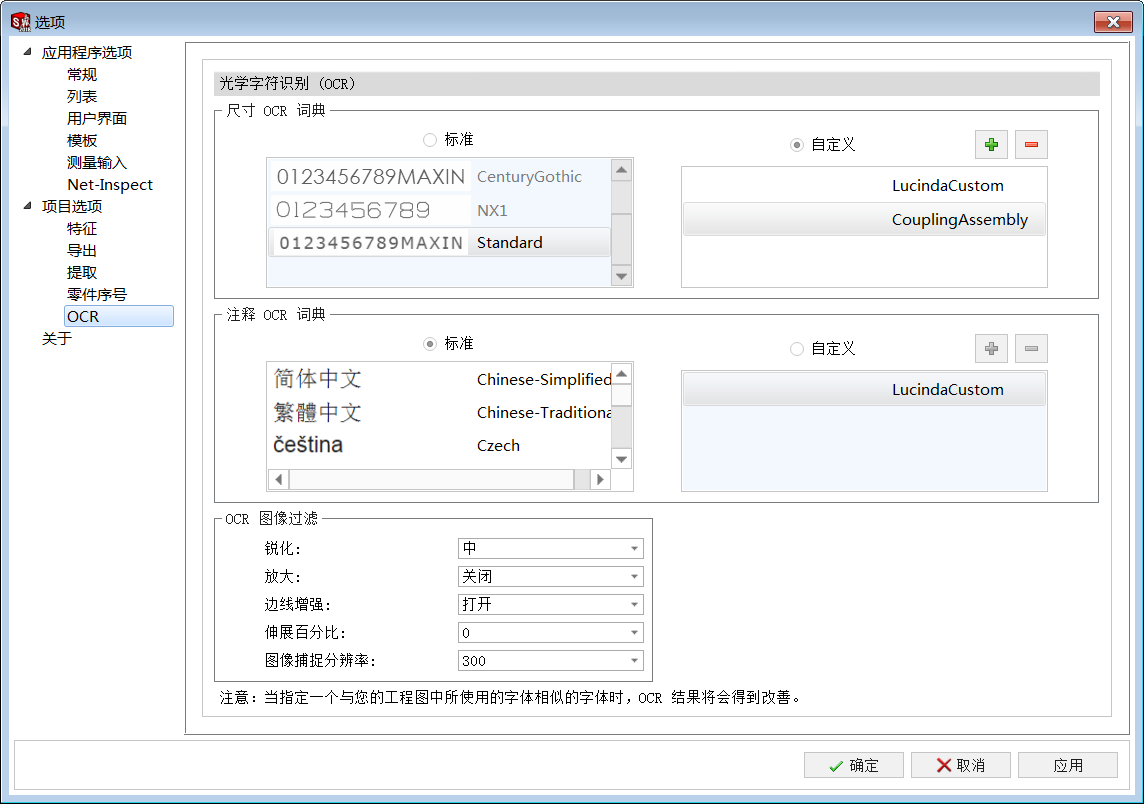
圖 8選項設置
7.單擊確定後就可以使用我們自定義的詞典對工程圖進行OCR識別了。
【結果對比】
我們打開一幅用非標准字體繪制的工程圖,用默認Standard字體進行標號,發現尺寸識別正確率不高,如下圖所示,字母R識別成了72,小數點沒識別到。

圖 9錯誤識別
使用自定義的詞典字體之後,我們可以發現該尺寸識別正確
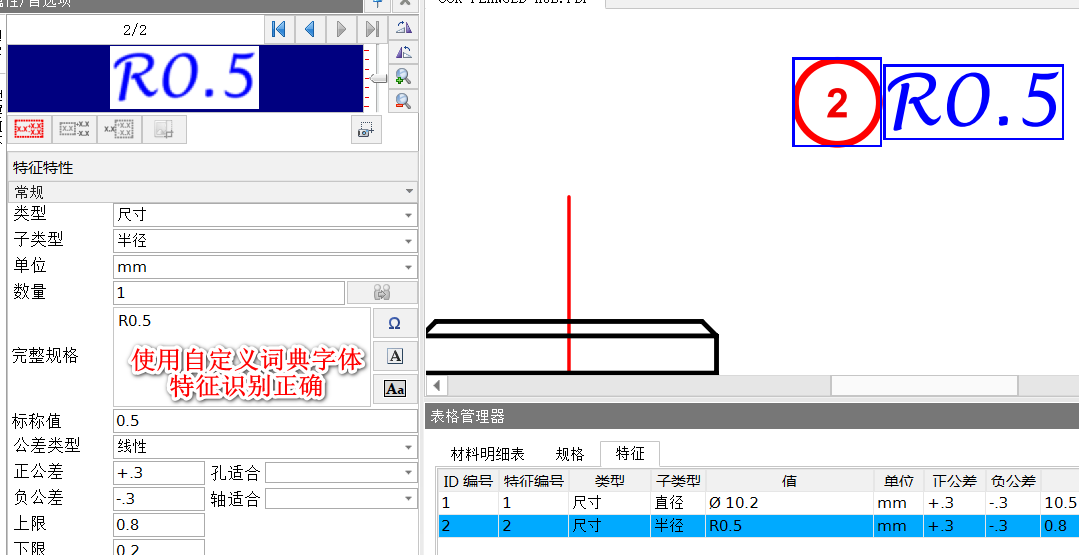
圖 10自定義詞典正確識別
【總結】
雖然Inspection官方已經為客戶提供了相當完善的詞典字體,能夠滿足大部分主流工程圖紙的識別。但是仍有部分字體沒有覆蓋,並且OCR引擎對於字體庫的匹配非常嚴苛,與字體庫稍有不同就可能識別錯誤,需要手動修改,影響工作效率。所以在遇到多份字體相同、使用官方提供的詞典字體識別正確率不高的時候,創建一個自己的詞典字體就顯得很有必要了。我們只需要創建一次詞典文件,在遇到同樣使用該字體的工程圖的時候,選擇自己創建的自定義詞典將大大提高OCR識別的正確率,提高我們的工作效率!